Not many can claim 25 years on the Internet! Join us in celebrating this milestone. Learn more about our history, and thank you for being a part of our community!
Gnollrunner said: Super. For some reason many people think converting to double is going to be way harder than it really is. But as I said, unless you are tied to a game engine, it's really quite simple in most cases.
Wasn't hard for sure. But incredibly tedious considering the number of changes I had to make (a lot). That said, if I hadn't found this math API, I wouldn't have bothered because I'd rather take a hot poker to the eye than write my own math routines. I hate math. I know, I'm in the wrong profession.
Gnollrunner said: Just as a heads up…… If you are still using 32 bit float matrixes on the GPU side and you find you still have some jumping issues, I might suggest pulling the projection part out of the matrix and doing it as a post step. This was one issue I had, and that solved it
Interesting. Can you elaborate on what you mean by pulling the projection out and doing it as a post step? (I'm not running into any issues here, just curious and want to learn)
Interesting. Can you elaborate on what you mean by pulling the projection out and doing it as a post step? (I'm not running into any issues here, just curious and want to learn)
First I'll say I've never done graphics in C# before so I'm not 100% sure the same stuff applies. However often in things like DirectX or OpenGL you have a 4X4 transformation matrix that changes for whatever objects you are drawing . It's often considered to incorporate 3 parts: World, View and Projection (although I have heard it called otherwise). Doing World/View is pretty straight forward as you are just combining various transformations for your objects and camera. It doesn't even use the last column (or row depending on how you think of it) of the matrix. In my case I do this all in double on the CPU. To go to the GPU I send down the final matrixes converted to single precision float. At no point on the GPU do you want to go to World space. Some shader code I've seen does this and it works fine at smaller scales but for large scale stuff you will reintroduce your precision problems. If it's working for you now, it sounds like you aren't doing this anyway.
The final part of the WVP matrix is the projection. That introduces some tricks and does use the last matrix column. This worked OK for me initially, but still at very long distances I started to have some problems of things jumping around and flickering. What solved it was just getting rid of the projection part of the matrix and doing it by normal math. For projections you are basically just taking lines from the vertexes transformed by your matrix which are now in view space ( i.e. The camera is at (0,0,0) looking down Z for right hand or -Z for left hand), and projecting them though a plane one unit from the camera, to the camera point.
Also DirectX and OpenGL expect numbers in a certain range of Z. I believe for DirectX it's 0 to 1 and for OpenGL it's -1 to 1, but don't quote me on that. What that means is you have to compress your Z into that range. This calculation also typically goes into the projection part of the matrix. The problem is most projection matrices designed for shorter distances, give you Z-fighting at range. What I ended up doing is just dividing all my Z values by a huge power of 2. My reasoning was that by doing this the calculation shouldn't touch the mantissa and only tweak the exponent, so there is no chance of it messing up the depth, at least in that step. This actually worked great for me. There may be a way to actually get it to work in the matrix but I got tired of messing with it so I just settled on this.
I'm not really sure if any of this stuff applies to you since you aren't doing 3D and perhaps you aren't doing graphics at this low a level. But I thought I'd throw it out there.
Gnollrunner said: World, View and Projection (although I have heard it called otherwise)
Likely you mean Model, View and Projection (MVP matrix), where the model matrix transforms your local object coordinates to worldspace, so it's just a matter of semantics.
If our model ends up at big number coordinates in world space, but the view transform pulls them back to the origin anyway, we surely can avoid redundant large number precision issues by being careful. I guess part of the Floating Origin proposal using the top level inverse transform is to make sure - while large numbers happen - that the resulting error is shared across the entire scene and the view, and thus not observable.
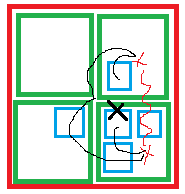
I still have not read the paper about resolution spaces, but i can imagine to make such idea work we could do this: Example: Large 2D world, and we divide hierarchically like multiresolution grids. Top level: 1 huge root cell; Second level: 2x2 cells parented by the root, Third level: 4x4 cells, parented by the closest cells from the 2nd level. And so on. This gives us a problem:
We are at the black X. Resolving the transform hierarchy, we get a huge distance (wavy red line) at level one (green cells).
Thus the neighboring level-two-space (blue) may jitter relative to the current blue cell we are actually in. But we can solve this using adjacency links from each cell to their neighbors, so we don't have to walk to the root - instead we build the neighboring transform from the link to the current one. This way again all error is shared and not observable, even across the boundary to neighboring spaces. And this way, Star Citizen could actually work without a need for doubles.
Pretty sure this works. Will try it out when i'll work on runtime engine. For my current work on editor and tools, i still have to use doubles. Because i must ensure coordinates match exactly across boundaries, and i can not work on a floating position. I need the exact same numbers from anywhere. No way around high precision world space coords using doubles. :/
Gnollrunner said: World, View and Projection (although I have heard it called otherwise)
Likely you mean Model, View and Projection (MVP matrix), where the model matrix transforms your local object coordinates to worldspace, so it's just a matter of semantics.
Frank Luna calls it WVP, you call it MVP, I call it Leroy.
Gnollrunner said: First I'll say I've never done graphics in C# before so I'm not 100% sure the same stuff applies.
Oh, that's not really relevant when dealing with linear algebra and the like. It only matters when dealing with SIMD stuff. I know that you can have intrinsics in .NET, but it's not a trivial thing from what little I've learned about it.
Gnollrunner said: However often in things like DirectX or OpenGL you have a 4X4 transformation matrix that changes for whatever objects you are drawing
Yep, fully aware of that. I was just wondering how you were going to project from object space → world space → screen space without using a projection matrix. My rendering API doesn't have a world/model matrix, as all the vertices for the sprites are transformed using trig/basic math prior to uploading to the GPU (I've profiled this and I've found matrix multiplication to be a bit slower than doing it this way). Basically all my vertices are transformed, written to a buffer, and when a state change occurs or the buffer is full, only then is it issued in a draw call. This is pretty common procedure for 2D stuff. The only point where I'm multiplying by a view and projection matrix is in the vertex shader. In fact, give how sprite batching works, I can't submit a world matrix at all, it just wouldn't work.
Gnollrunner said: What solved it was just getting rid of the projection part of the matrix and doing it by normal math
This is the part that I'm interested in. Are you saying you project the vertices manually to projected space just using basic math?
Gnollrunner said: I'm not really sure if any of this stuff applies to you since you aren't doing 3D and perhaps you aren't doing graphics at this low a level
The Z stuff does not apply since I'm using 2D. Well, it doesn't apply in that I don't use it to project into depth, but I do use it for masking via the z-buffer (mostly for post processing). And for this application, no, I'm not doing things at that low of a level. The low level stuff happens in my API. This application isn't really a game as such, it's more a toy box so I can test my API functions/features. That said, I wanted to learn about handling large coordinate spaces just for my own knowledge, thus we have this thread.
If our model ends up at big number coordinates in world space, but the view transform pulls them back to the origin anyway, we surely can avoid redundant large number precision issues by being careful. I guess part of the Floating Origin proposal using the top level inverse transform is to make sure - while large numbers happen - that the resulting error is shared across the entire scene and the view, and thus not observable.
I'm not sure I follow what you mean about resulting error shared across entire scene, but I think I follow your proposed solution. This harks right back to Dungeon Siege, which divided space up like this. And that is fine. Dividing the space into smaller chunks helps you have smaller problems in the chunks and you can manage loading unloading data / levels in smaller pieces.
Going back to the fundamentals, the general problem we are talking about is achieving a high fidelity and high performance view, of a relatively small region of interest, inside a much larger reference space. With respect to shared space and error, some relevant facts are:
floating point space is a nonuniform field and therefore the gap error between points varies across the field.
Scenegraph nodes inherit the resolution error at the position they are in and that will always be different from other nodes positions.
One thing that is shared (and this might be what you are thinking) is the spatial error of the parent nodes of all siblings, all the way back to the root node.
I still have not read the paper about resolution spaces, but i can imagine to make such idea work we could do this: Example: Large 2D world, and we divide hierarchically like multiresolution grids. Top level: 1 huge root cell; Second level: 2x2 cells parented by the root, Third level: 4x4 cells, parented by the closest cells from the 2nd level. And so on. This gives us a problem:
We are at the black X. Resolving the transform hierarchy, we get a huge distance (wavy red line) at level one (green cells).
Some of the early systems I reviewed for my thesis, like Dungeon Siege, used a sector/chunk model to help manage limitations of precision across larger spaces.
However, they:
Did not recognise or directly exploit the nonuniform nature of floating point space: e.g. super high resolution at the origin.
Sectorisation introduces boundary problems, as you note, which complicates design and algorithms.
There was no fundamental change of thinking : everything was based on absolute space and position with fixed subspaces and boundaries.
Therefore, there was no fundamental change of solutions.
Thus the neighboring level-two-space (blue) may jitter relative to the current blue cell we are actually in. But we can solve this using adjacency links from each cell to their neighbors, so we don't have to walk to the root - instead we build the neighboring transform from the link to the current one. This way again all error is shared and not observable, even across the boundary to neighboring spaces.
Dynamic approaches like this, where you have an application pipeline stage with no fixed boundaries is a move in the right direction. In that respect, it has similarities to my dynamic approach.
An aside. the sectored model is still pretty much necessary because we need reference maps from, which relative positions can be derived, whether they be symbolic or in a fixed coordinate representation, or a combination. This part I pushed to the back end of an application pipeline: in client or on server or a combo, but away from the (pseudo) realtime frame-by-frame processing. I put translation stage(s) between the reference system and the performance output stage. With your ideas above you are starting to do the same.
Pretty sure this works. Will try it out when i'll work on runtime engine.
I think it will, at least heading that way.
Then, [continuing my design outline] the high performance application and output stages can have a single continuous relative space model with mapping from reference system handled (chunk style) in the slower back end.
And this way, Star Citizen could actually work without a need for doubles.
Yes, more use of floats at the front end.
Do you work on Star citizen?
For my current work on editor and tools, i still have to use doubles. Because i must ensure coordinates match exactly across boundaries, and i can not work on a floating position. I need the exact same numbers from anywhere. No way around high precision world space coords using doubles. :/
And that is always true: there needs to be a reference map/system that has all the information with accurate local coordinates and from which the local and relative positions are derived.
This is the part that I'm interested in. Are you saying you project the vertices manually to projected space just using basic math?
Yes I do it after the matrix transformation. I mean every value generated by matrix multiplication takes 4 multiplies and 3 additions. I guess for really large values the intermediate results were an issue. Without an in depth analysis I can't say what the exact problem was but that's my guess since doing it the gradeschool way solved it.
I'm not sure in 2D you even need projection however. You could just use scaling if everything is on the same plane.
dragonmagi said: One thing that is shared (and this might be what you are thinking) is the spatial error of the parent nodes of all siblings, all the way back to the root node.
That's what i meant with ‘shared error’, yes.
dragonmagi said: However, they: Did not recognise or directly exploit the nonuniform nature of floating point space: e.g. super high resolution at the origin.
Sectorisation introduces boundary problems, as you note, which complicates design and algorithms.
There was no fundamental change of thinking : everything was based on absolute space and position with fixed subspaces and boundaries.
But notice that my proposal tackles all these 3 points: World space coordinates are no longer needed anywhere, so we can have an infinite sized world. We even calculate our transforms relative to the origin, using the adjacency graph including spatial offsets, instead a traversal from the root using positions. To do so, we need to track the camera relative to it's current and parent nodes. This gives us potentially large numbers only for tree levels near the root, which are only used to display low detail objects like distant stars or galaxies. Range of precision is optimal for any scale.
Boundary issues are prevented by using adjacency offsets. As said, a low level adjacent space will have a large offset, truncating fine details of current camera position. But this error does not propagate down to its children. Because we resolve those children with adjacency offsets as well, which will be smaller than for the parent level. Accuracy increases as we move closer to the camera.
The change in thinking is quite big. Beside dropping world space coords. We also may replace a bottom down tree traversal with a breadth first graph search, to find the set of relevant nodes of our scene graph. We may even use Dijkstra to get a robust order of which transforms to build from which neighbors.
So this should resolve both potential issues i still saw from your first FO paper: Building the parenting inverse transform might involve too large numbers to represent fine grained camera movement. And neighboring sets of objects may still diverge from the current set if their parent nodes are not the same.
Do you work on Star citizen?
No, i'm indie. Actually working on realtime GI and LOD tech which i want to sell if it works out. For demonstration i'll do some flat, large but detailed open world, so i'll run out of precision pretty soon i guess. I never believed porting CryEngine to doubles just to make a space game would be necessary and a good idea. I also think current games technology is too focused on just a single scale in general. Their solutions to the LOD problem are mostly just a bunch of hacks.
dragonmagi said: And that is always true: there needs to be a reference map/system that has all the information with accurate local coordinates and from which the local and relative positions are derived.
Though, following my proposal, the reference system would be no longer needed for the finished game at runtime. That's quite interesting, if i'm right.
However, there are many ways to have open world with single precision without extra cost. But the main problem i see is physics engines. Idk and have not yet looked up what functionality they have to enable this, without a need to constantly shifting stuff, eventually causing to rebuild acceleration structures. I'll need to discuss this with physics dev and only after that i can decide for a solution to go.
So if you can talk about your experience with physics (or your papers already address this), would be very interesting… : )